Vous en avez marre de patienter à cause des limites des outils IA ? Et bien sachez que Julius Brussee s’est aussi retrouvé dans la même situation que vous. Originaire des Pays-Bas, ce jeune développeur a mis en ligne un skill pour faire parler vos LLMs comme des hommes des cavernes et par définition réduire sa consommation de tokens.
Réduire ses tokens IA
Pour beaucoup, utiliser des outils IA est devenu leur quotidien. On ne compte plus les développeurs qui ont arrêté de produire du code et qui à la place sont devenus des “superviseurs” (façon Fallout). Ils définissent et contrôlent ce qui est à faire ou ce qui a été fait. Le revers de ce changement de paradigme, c’est qu’on consomme de facto plus d’IA qu’auparavant, et on va en demander plus à nos hébergeurs.
Alors qu’à ses débuts on faisait du copier/coller de code dans l’interface de ChatGPT, aujourd’hui on a des outils qui s’exécutent en ligne de commande (Claude, Codex, OpenCode, Crush et j’en passe). Ces logiciels peuvent analyser notre base de code (la codebase pour les anglophones parmi nous), nous donner des recommandations, ajouter des fonctions ou encore corriger des bugs. Bref, tout ce qu’on faisait avant de manière artisanale (c’est Arthur Mensch qui l’a dit devant le sénat), l’IA le fait maintenant avec ses GPUs.
Pour fonctionner, l’IA lit et produit des tokens, grosso modo, c’est l’unité de mesure en IA (un peu comme des syllabes ou des bouts de mots). Selon les modèles, ces tokens se vendent plus ou moins chers, il n’y a qu’à voir les tarifs sur OpenRouter pour en avoir une idée.
Les modèles se commercialisent au million de tokens. Les hébergeurs comptabilisent donc les tokens en entrée et en sortie. C’est double peine, chaque bout de code lu ou chaque bout de code produit se paye.
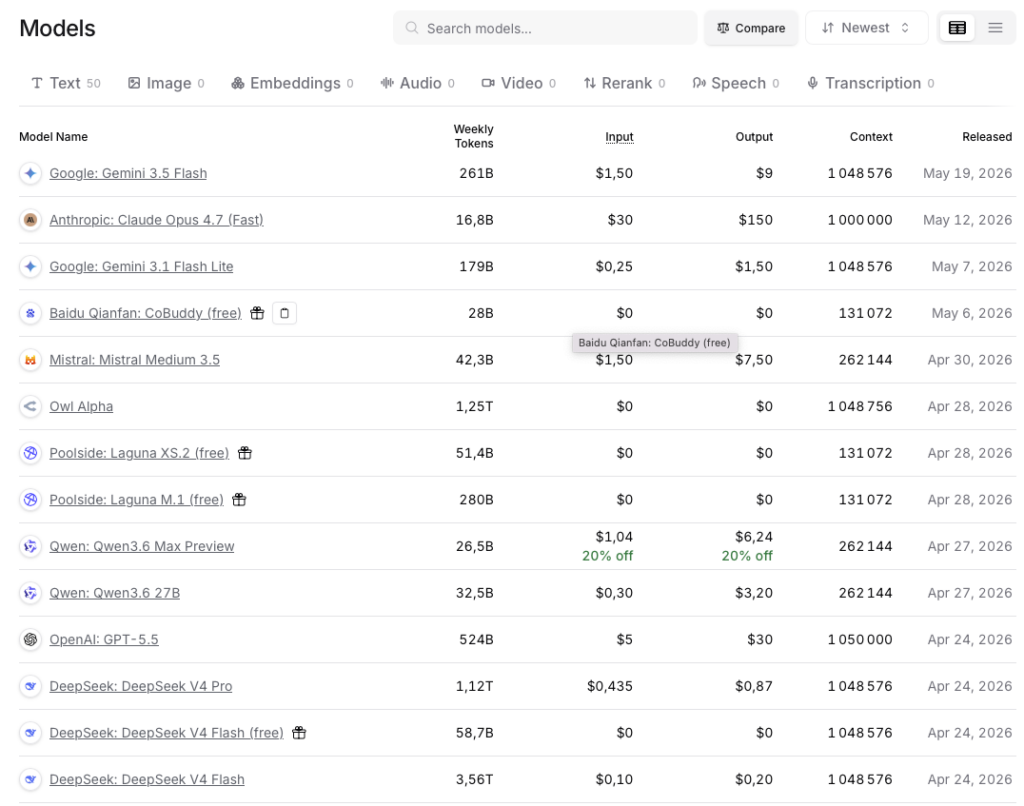
Actuellement on retrouve Gemini 3.5 Flash à 1,50 $ le million de tokens en entrée et 9 $ le million de tokens en sortie. Opus 4.7 chez Anthropic est à 30/150 (30$ en entrée et 150$ en sortie), ce qui est quand même assez salé, même pour un modèle haut de gamme.. Vu ces tarifs, vous comprenez qu’il est vite essentiel de trouver une façon de faire une économie sur son usage IA. C’est là qu’intervient Caveman.
Installer et utiliser Caveman
Caveman est un skill Claude disponible sur GitHub dont l’objectif est de limiter le nombre de mots en sortie des LLMs. L’idée est simple : il force votre IA à répondre le plus court possible pour économiser des tokens, du contexte (fenêtre de travail), votre abonnement ou surtout vos précieux sous-sous si vous tapez directement sur l’API.
Avant tout vous devez avoir NodeJS 18+ installé.
Voici les lignes pour installer Caveman :
# macOS / Linux / WSL / Git Bash
curl -fsSL https://raw.githubusercontent.com/JuliusBrussee/caveman/main/install.sh | bash
# Windows (PowerShell 5.1+)
irm https://raw.githubusercontent.com/JuliusBrussee/caveman/main/install.ps1 | iexUne fois exécuté vous aurez un rapport d’information concernant l’état de l’installation.
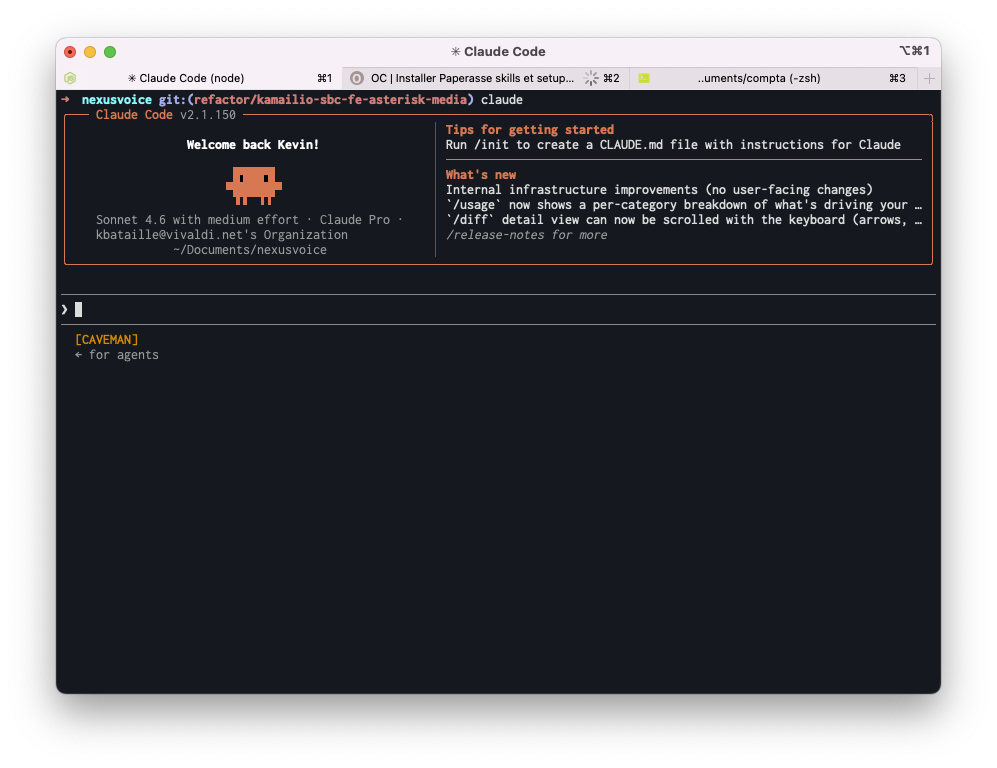
Caveman sera automatiquement lancé au démarrage de Claude et vous verrez le “[CAVEMAN]” affiché sur votre écran. Fini les emojis, les longues phrases et les longs développements, votre agent IA va droit au but.
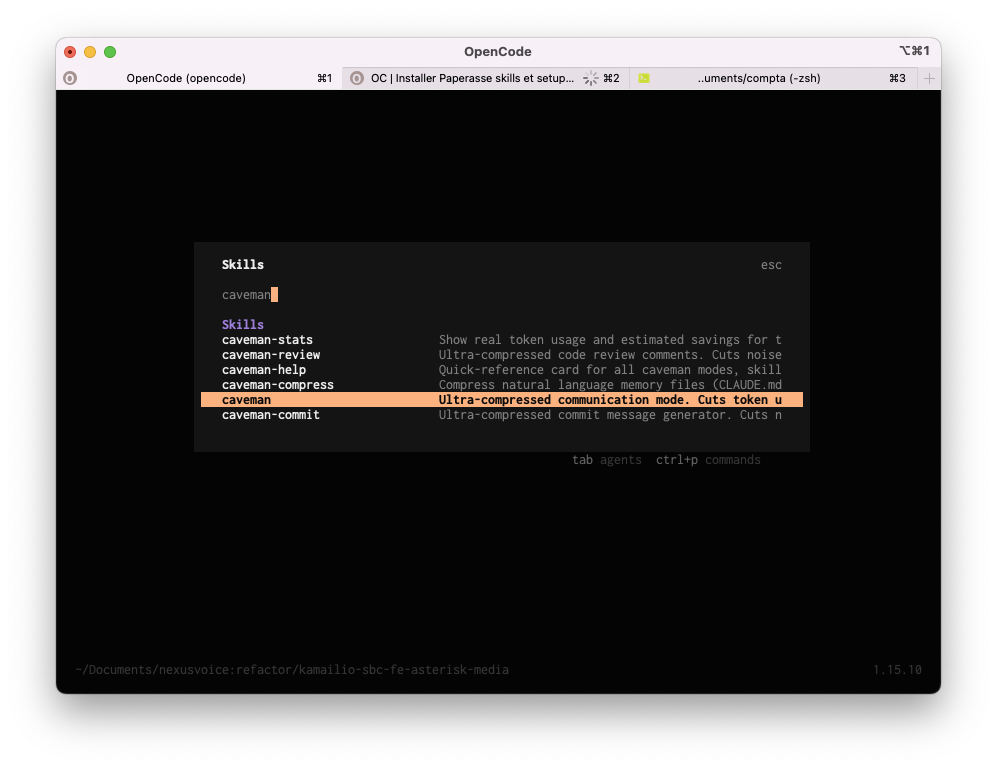
Dans OpenCode, pour activer caveman il faut taper /skills puis sélectionner caveman pour le lancer.
Voilà, avec ça vous devriez pouvoir faire durer tes sessions un peu plus longtemps sans exploser vos budgets tokens. Dans le doute je replace le lien officiel du dépôt ici : Caveman